
在本期文章中,我们将继续介绍一些AI图像生成工具,包括MidJourney、DALL-E和Stable Diffusion等。与之前的分享不同,本期将着重介绍MidJourney和Stable Diffusion的图像生成方法,为大家带来更为实用的知识。这次的分享可谓是干货满满,千万不要错过噢!
(本文内容基于同事何胜友在公司内部分享的PPT,PPT分享时间为2023年3月9日。)
AIGC是什么
AIGC(AI-generated content)是指由人工智能算法生成的各种文本、图像、音频等内容,其中涉及到自然语言处理(NLP)、计算机视觉(CV)、语音识别(ASR)、语音合成(TTS)等技术。通过对大量数据的学习,AI模型可以生成高质量的内容,并且可以根据特定的需求进行定制化生成,极大地提高了内容创作的效率。在新闻、广告、社交媒体、网站、游戏等领域得到了广泛的应用。
图像生成是什么
图像生成是AIGC的重要组成部分,是一种基于人工智能的图像创建技术,该技术可以根据给定的输入(如文本、图像或视频)生成新的、令人惊叹的图像。AI图像生成技术依赖于机器学习,可以自动学习、分析和生成图像,而不需要人工干预。
图像生成工具有哪些

热门工具介绍
1、MidJourney
MidJourney占据着主流地位,凭借卓越的效果和简单易用的操作而闻名。它提供了详尽的文档,帮助用户轻松上手。与其他类似工具截然不同的是,MidJourney独有的功能是能够识别图片作为提示词,为用户提供更多样化的体验。此外,MidJourney采用包月制的收费形式,并附带算力限制,以满足不同用户的需求。


2、Disco Diffusion
Disco Diffusion在图像输出方面表现稳定,相同参数下生成的图像大致相似,因此更适合进行细节和局部的修改和微调;然而,它在创意方面稍显不足,惊喜不多,并且速度较慢。其特点包括对增强现实的支持,以及独有的3D动画模式(可设定3D摄像机轨道)。网上常见的吐槽:教程与视频晦涩难懂。
(3D动画在写PPT的这几天已经不是独有了,SD deforum插件面世。)

3、DALL-E
DALL-E是一款功能强大且多样的工具,但由于它是一个大型模型,只能在云计算环境中使用。其开源版本提供了论文和源代码,但对非专业人员来说可能有些难以适应,因此一些轻量级模型如Craiyon(DALL-E Mini)衍生而出。然而,这些轻量级模型在图像生成效果上大打折扣,几乎在同类工具中排名垫底。
 |  |
4、Stable Diffusion
Stable Diffusion最热门的开源项目,出图较快且观赏性高,自由度高,硬件要求低,方便的模型再训练和prompt使其能天马行空,适合搞创意,对细节进行调整时不如DD(DALL-E),对英文prompt的熟练度要求很高,提示工程师由此而来。衍生出的主要模型有好几种,部分知名度已经超过Stable Diffusion本身,而辅助模型(针对画风、领域的独特模型)数量则已经达到上万种。围绕其开发的插件也非常多,能实现各种各样的功能。

热门工具对比

可见Stable Diffusion系列周边的热度不比MidJourney低。
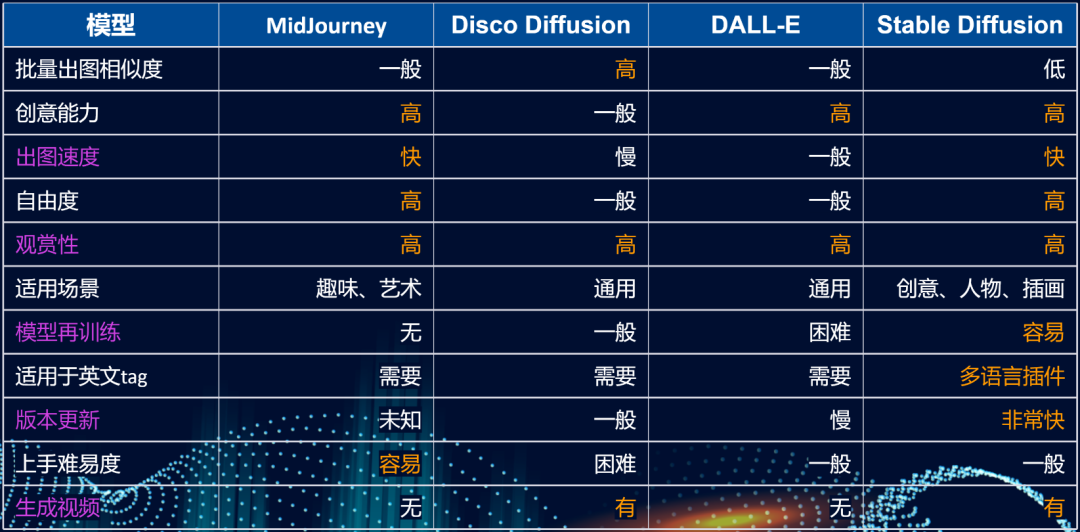
结论:如果您想快速上手且愿意付费,推荐选择使用MidJourney;而如果您偏向免费,则可考虑使用Stable Diffusion。
接下来我将重点为大家介绍MidJourney和Stable Diffusion。

特点
AI图像生成里的尖子生,无门槛、功能全、收费。
应用场景
适用于各类设计、表情包、插画等等。
功能介绍
MidJourney在4月份已经取消了免费试用,您可能需要考虑购买付费版本以获得更多功能和更长的绘图时长。

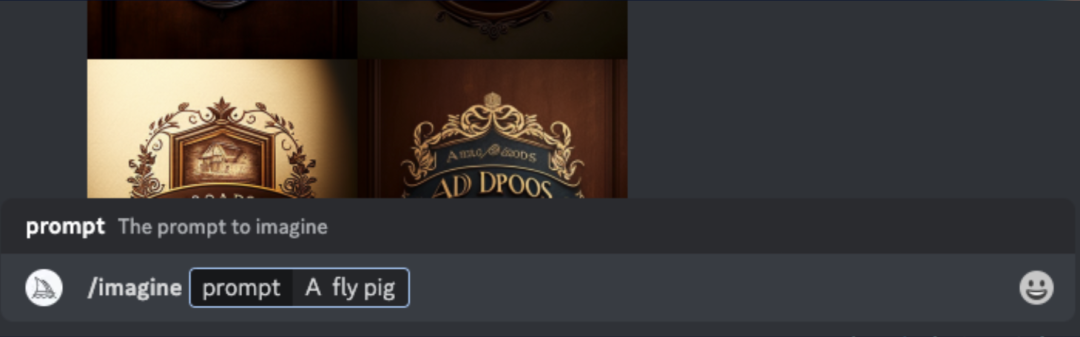
您可以在聊天框中直接输入命令"imagine",系统会提供智能提示来帮助您完成操作。
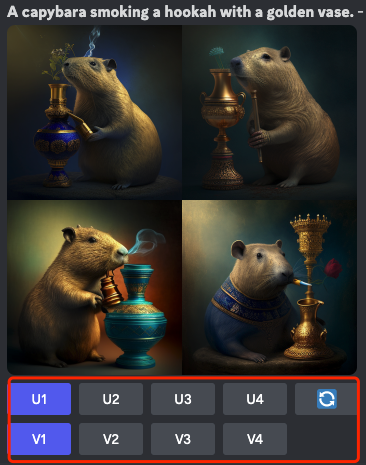
U1-U4:用于选择不同的放大方式。您可以根据需要选择其中一个选项来放大图像。每个选项可能使用不同的算法和参数,以达到不同的放大效果。
V1-V4:这些选项用于选择不同的优化改良方式。一旦图像被放大,您可以选择其中一个选项来对放大后的图像进行优化和改良。每个选项可能应用不同的技术和算法,以改善图像的质量、细节或其他方面。

Make Variations:使用此按钮可以创建放大图像的不同变体。选择一张图像进行放大,并使用此功能生成四个不同的变体选项。这些变体选项将以新的网格形式呈现。
Beta/Light Upscale Redo:使用此功能可以生成不同比例的图像。
Web:使用此功能可以在网页中直接打开图片。
MidJourney还提供了表情图片来表示对生成图片的满意度。这些表情图片可以反映用户对生成结果的喜好程度。
此外,根据官网的说明,订阅用户每天可以通过对图片进行评级来赚取免费的 GPU 绘图时长。具体的免费时长和优惠政策可能因官方政策的变化而有所调整。
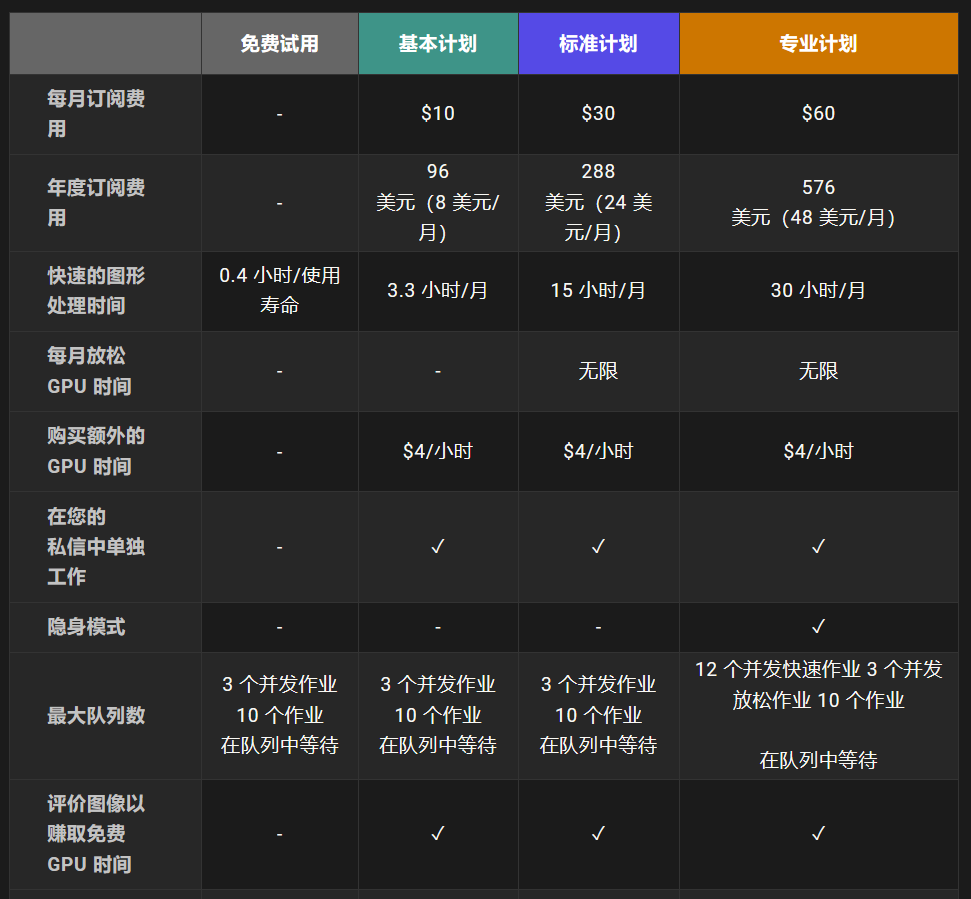
收费标准

特 点
主流模型,效果好、硬件门槛比较亲民、文档全,学习成本略高。
应用场景
已运用在艺术设计、视频制作、游戏开发等领域,具有广泛的应用前景。
功能介绍
文生图、图生图、图片修复、视频生成等。接下来我将详细介绍这4个功能。
Stable Diffusion-文生图
Stable Diffusion通过先进的扩散模型,能够生成高质量的图像。它利用迭代优化技术,将噪声图像逐步转化为逼真的图像,实现图像的生成和合成。


Stable Diffusion核心组件:WebUI(可视化界面),无需编写代码,方便用户操作。
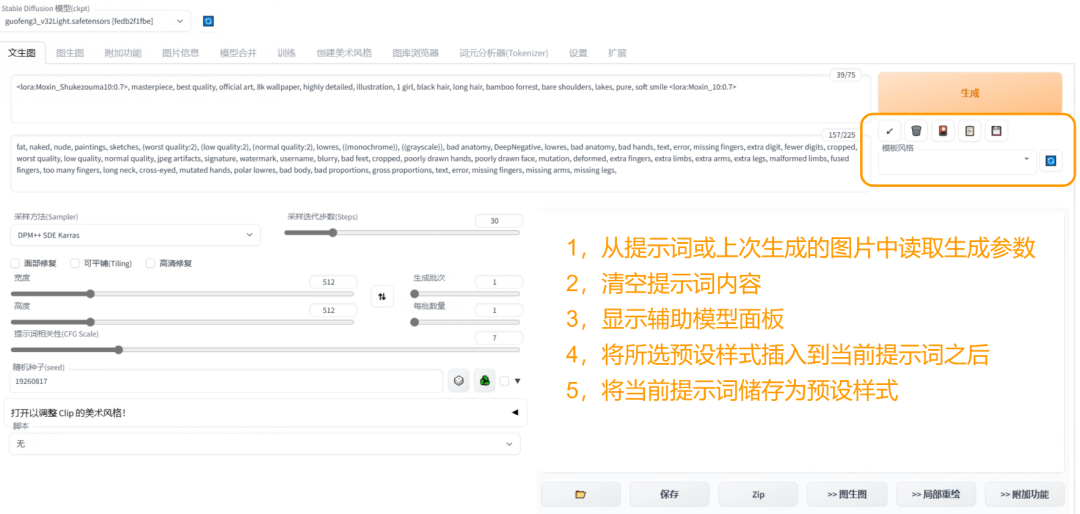
1、从提示词或上次生成的图片中读取生成参数。
2、清空提示词内容。
3、显示辅助模型面板。
4、将所选预设样式插入到当前提示词之后。
5、将当前提示词储存为预设样式。
主体模型


Lora模型
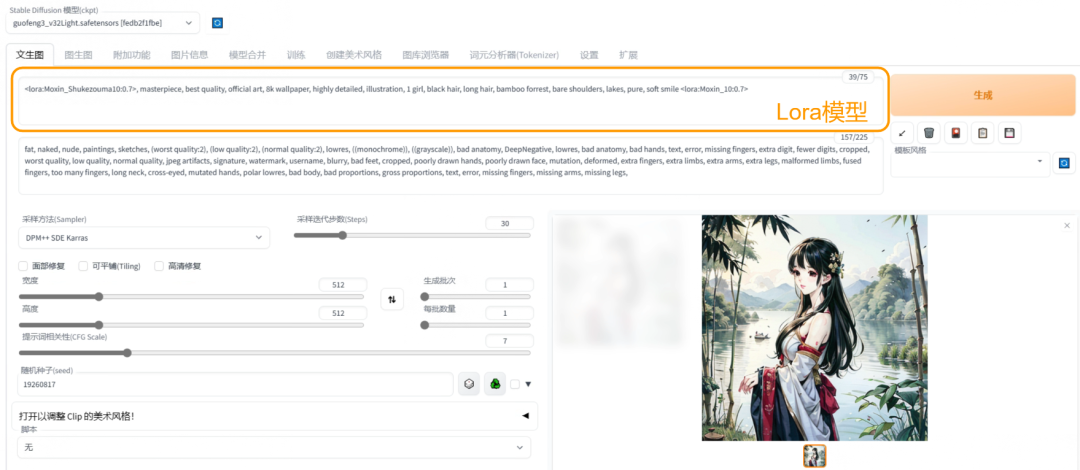
lora辅助模型的用法和主体模型不同,它是在提示词(prompt)里以固定的格式调用的,格式如下:<lora:辅助模型名称:干涉强度>
提示词(prompt)要求英文,一般为单词和词组,使用英文逗号隔开,使用句子或段落也可以,但效果不好。
shukezouma, negative space, , shuimobysim , traditional chinese ink painting, <lora:Moxin_Shukezouma11:1>,
<lora:Moxin_10:0.5>,sam yang, 1girl, black eyes, black hair, blue sky, cityscape, clear sky, coat, day, earrings, eyewear hang, eyewear removed, fur coat, jacket, jewelry, long hair, looking to the side, outdoors, power lines, red lips, sky, smile, snow, solo, sunglasses, white bird, white coat, winter, winter clothes , ((masterpiece))

从上到下,从左到右,水墨风格lora模型的权重在依次降低
格式与权重:
1、提示词越靠前权重越高。
2、( ) 提高0.1倍的当前权重,可多层嵌套。
3、[ ] 减弱0.1倍的当前权重,可多层嵌套。
4、(提示词0.5)和(提示词1.2)的写法。
5、用|连接多个提示词,可以混合效果,blue hair | red hair 。

输入反向提示词(negative prompt)
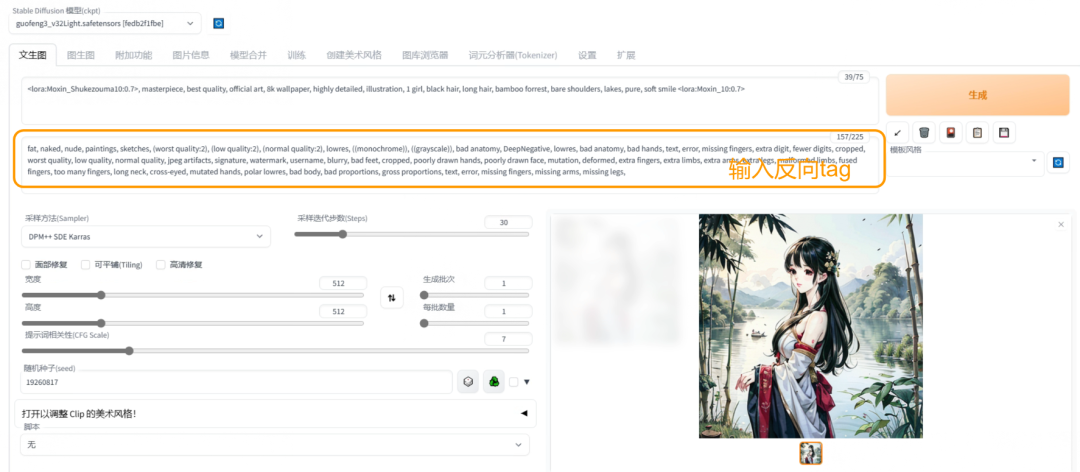
💡反向提示词:(worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, skin spots, acnes, skin blemishes, age spot, (watermark:2),
(最差品质: 2) ,(劣品质: 2) ,(正常品质: 2) ,低品质,正常品质,皮肤斑点,痤疮,皮肤瑕疵,老年斑,(水印: 2)

Sampler(采样方法)
采样器,影响生成速度和风格。
Steps(采样迭代步数)
步数越高,生成效果越好,但生成时间会增加。建议从20开始。


4种不同的采样器生成出来的效果

不同的采样迭代步数产生的画面差异
高度、宽度设置
高宽影响构图、速度和质量。
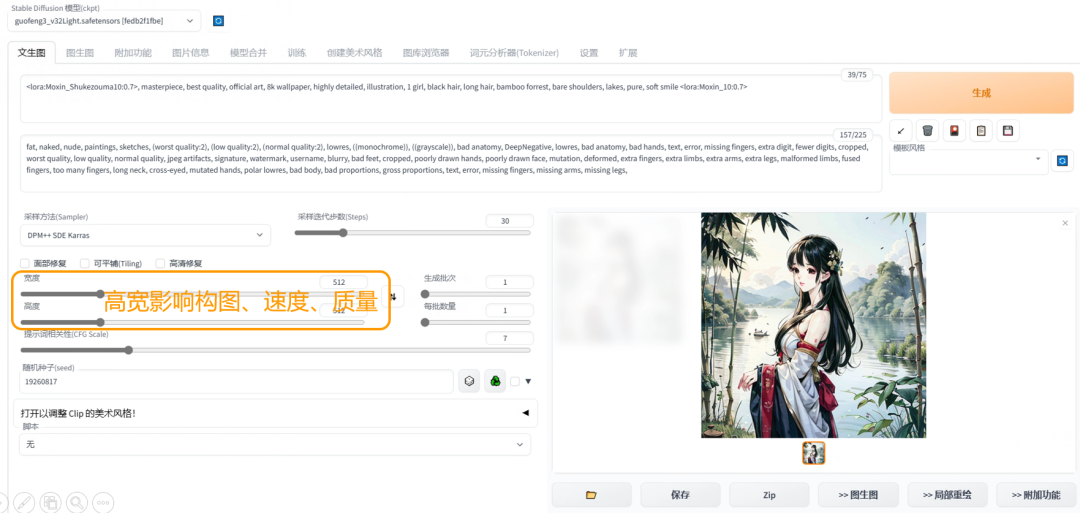

高度和宽度对画面内容和质量的影响
CFG Scale(提示词相关性)
相当于prompt整体权重,数值越大越参照提示词。
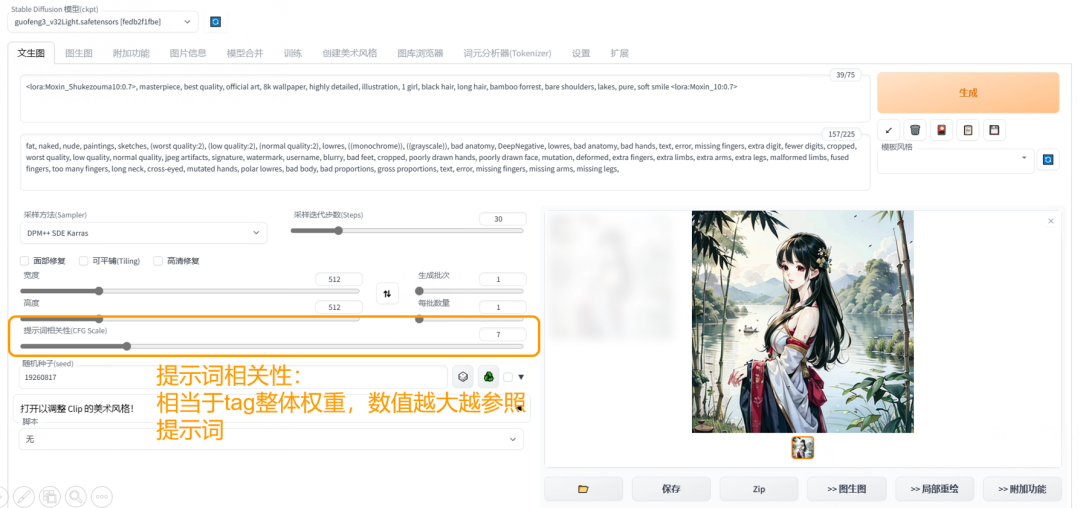

提示词相关性由低到高对画面的影响
Seed(随机种子)
每张图片都有独特的种子,这些种子用于确定扩散的初始状态。换句话说,通过使用另一张图片的种子,可以使构图、元素、物体等各个方面都非常接近。默认值为-1,即随机种子,可以产生更多的创意。如果想要模仿某张图片,可以使用该图片的种子。在模型、Lora、提示词、分辨率、采样、提示词相关性和种子都相同的情况下,可以完美复制同一张图片。

随机种子的数值由低到高生成的画面
Stable Diffusion-图生图
选项及设置和文生图基本一样,但要求对文生图的熟练度有更高要求,尤其是模型的选取、prompt、采样、重绘幅度、提示词相关度。

上传图片后点击反推提示词,Stable Diffusion的算法能够帮你从图像中提取出一些关键词
Stable Diffusion-图片修复
Stable Diffusion具有图像修复的能力,可根据输入的损坏图像,通过图像重建和修复算法,恢复图像的缺失或损坏部分。

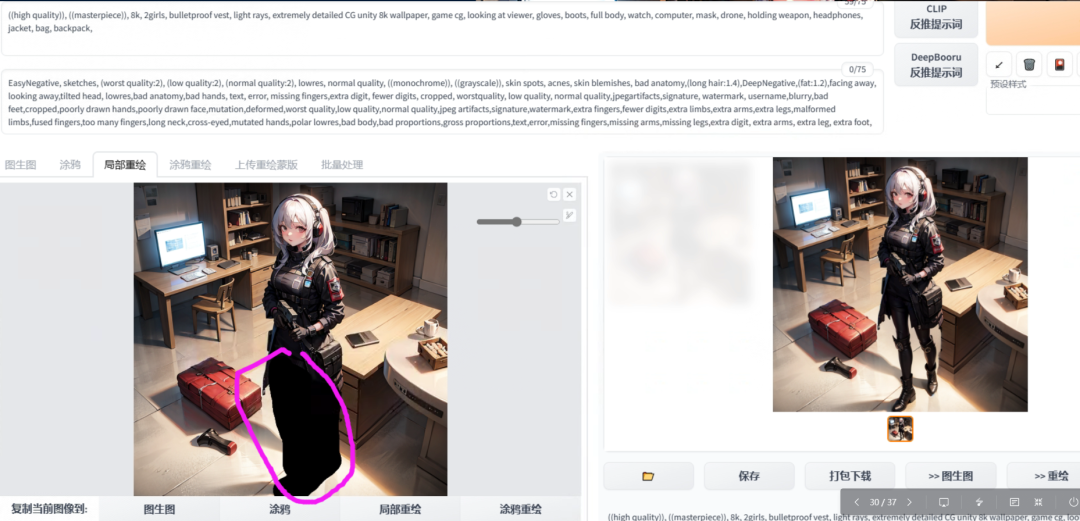
点击局部重绘,涂抹想要修改的区域,并输入目标效果的提示词,生成即可
💡如何提高图像生成的效果和质量?
使用AIPRM浏览器插件让ChatGPT帮我们写提示词,再去生成,更方便快捷,要求高的可以继续修改和增补提示词。
模型:主体模型和lora模型,选择你想要的风格和内容方向,市面已有数千种主体模型和上万种lora模型。
提示词:要花更多的精力在prompt的写作研究上。lexica.art、openart.ai
炼丹:训练自己的模型或融合多种不同的模型达到自己的定制需求,门槛不高,8G显存起步,饲料数量需求很小。
Stable Diffusion-视频生成
Stable Diffusion在影像方面比图像也足够惊艳,技术迭代可谓日新月异,一个季度前才让插画师感到难受,现在压力又给到动画行业了。
以下功能都是Stable Diffusion的插件,均为开源项目。视频功能学习成本和门槛都比较高,高配显卡生成15秒视频耗时5-10小时。笔者入门时生成一个粗糙的3秒视频就花了半小时。
control net 3D 骨架系统,现已迭代至1.1 👇  | vid2vid 和 loopback 快捷但质量一般 👇  |
抽帧+图生图+AE转为视频 质量最高,代表作石头剪刀布 👇 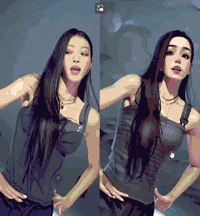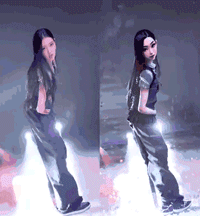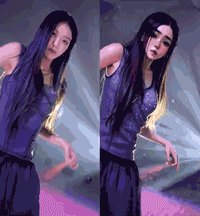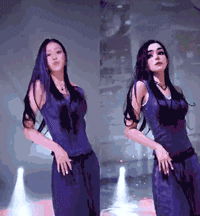 | Automatic 1111+deforum文生视频 Disco Diffusion同款3D视角视 👇  |
版权问题
MidJourney等商用模型声称其生成的图片具有可商用的版权。然而,美国版权局在2月23日的声明AI图像不受版权保护,即使通过再次训练或多模型融合得到的图像,也没有版权保护。但AI图像在二次创作和修改达到较高的程度后(能判断出你才是主创作者或主脑才行)还是可以的。
现在相关法律还不完善,也可能会随着时间还会有很大变化。
Stable Diffusion安装
(按步骤来,少走几天弯路噢~)
1、按B站秋叶的教程安装Stable Diffusion(简单,教程只有安装过程,不含以下的优化和设置)
2、huggingface.co 下载主体模型,目录:\models\Stable-diffusion。初次使用推荐下载anything v4.5模型,以后按自己喜好选择
3、下载自己喜欢的辅助模型(Lora),改变质量和风格偏好,目录:\models\Lora
4、下载变分自编码器(VAE):vae-ft-mse-840000-ema-pruned,不用下别的,目录:\models\VAE。
5、在根目录打开启动器,在高级选项里选中显卡(默认CPU),点击启动,找不到显卡请更新驱动。
6、Wait a moment,之后会自动打开webUI。
7、启用VAE,在webUI界面,进入设置,找到Stable Diffusion👉模型的 VAE (SD VAE)👉vae-ft-mse-840000-ema-pruned 。
8、开启实时预览,设置👉range👉1
9、开耍🤖。
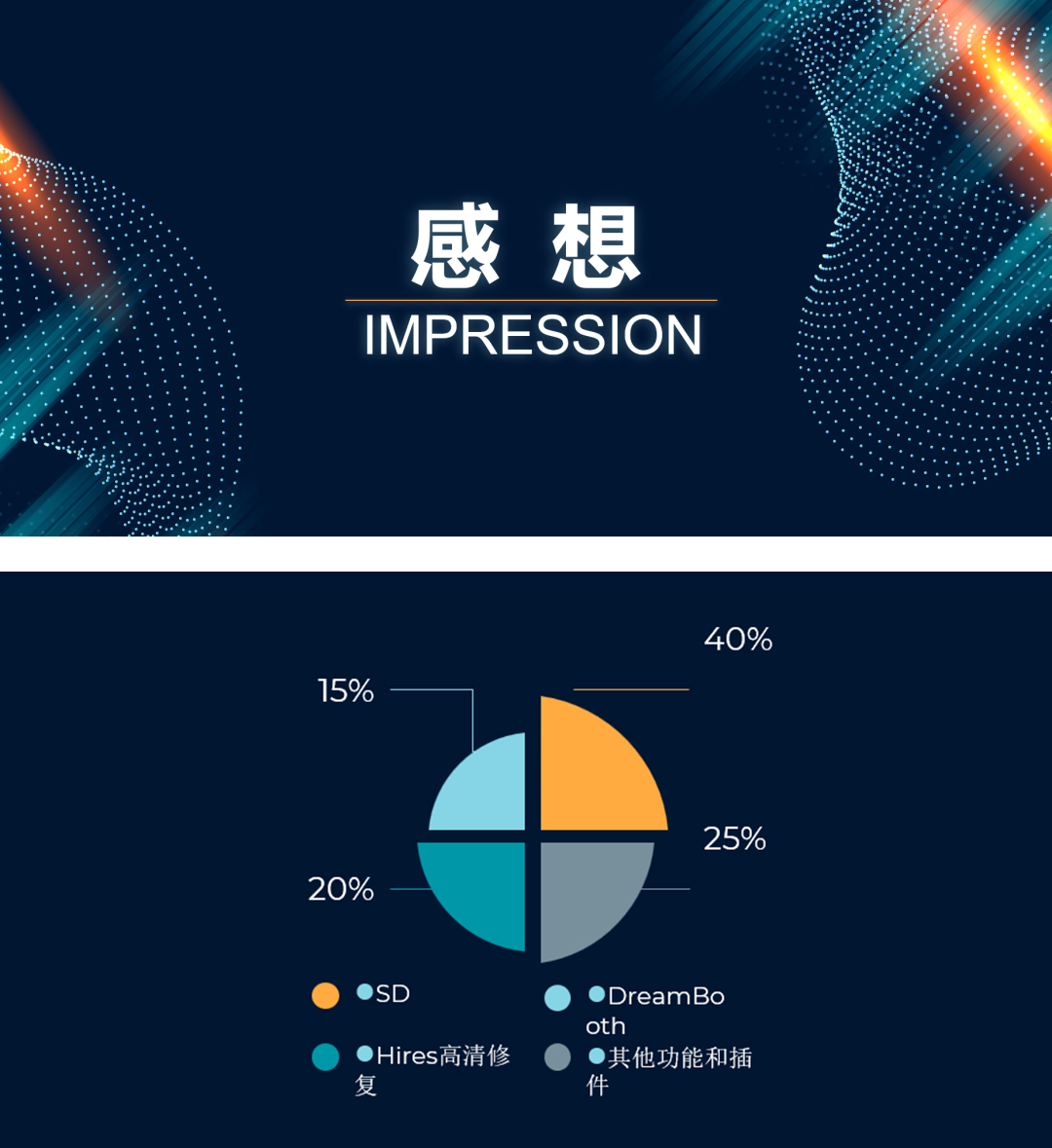
之前就听说Stable Diffusion的迭代日新月异,这次写PPT我切身感受到了。在过去的一个多星期里,我不断回头补充和修改新技术和新插件,因为它们与一个月前的视频教程相比,界面和功能都发生了很大的变化。

Stable Diffusion前不久又更新了一个大版本,这是用最新版本绘制的,画面精美了很多,能明显感受到技术的飞跃。
在我深入研究图像生成领域之后,才知道WebUI上的某个不起眼的选项或可能就是一篇上个月才刊登的最前沿的论文,而某些插件可能是多个先进算法的综合应用。以下是我了解的一些关于Stable Diffusion的发展历程和相关历史。
DreamBooth在11月面世后,较大幅度降低了模型训练的难度以及模型体积,模型数量开始井喷;Hires使图像细节和质量产生飞跃;随img2img的出现,诞生了vid2vid、插帧生成和骨架系统;VAE模型架构解决了图像生成中一直存在的色彩失真和细节缺失的问题;大部分图像生成都是GAN对抗网络的血脉;不少模型都有Google早期开源项目Transformer的影子。
感谢劲捷,这些年来我有机会接触到了一些与人工智能相关的人和事,负责过图像生成中的GAN神经网络以及自然语言处理(NLP)的项目。同时,我也非常感谢网络上的这些开源项目的贡献者,使我们能够近距离接触到这些科技前沿的产品。

过去我们听说过AI下棋、机器人会跑跳,似乎离我们使用AI还很遥远。然而最近几个月,AIGC席卷而来,彻底唤醒了我们。
作为网站开发者,我们曾对AIGC感到担忧,担心它是否会对搜索引擎和网站产生影响。但经过一段时间了解,我认为有影响但不会很大。流量可能会有些波动,但整个互联网有可能更加活跃。像ChatGPT这样的AIGC工具是基于互联网生态发展的,官方也提到网络上的数据目前还不足以支持其迭代训练速度。虽然它确实有取代搜索引擎的潜力,但可能不会,毕竟互联网是它赖以生存的土壤。
新Bing就是个利好互联网的例子,运用ChatGPT技术的新一代搜索引擎,为互联网的发展带来更多的创新、变革和机遇,它的出现是互联网又一次巨大的进步。
也许有一天我们会被AI超越,但现在我们应该专注于提升自己,并善用这些技术。也许未来人们讨论的焦点将不再是你能做什么,而是你能利用AI做什么。我相信这些技术将成为企业中最常见的生产力工具。
从现在开始,让AIGC帮助我们的网站,不要掉队,就可以了。
以上是本期文章的全部内容。在下一期的文章中,我们将继续与大家一起探讨AIGC的相关内容。敬请期待!
如果您希望探讨更多相关知识,请加入祁老师10多年前建的一个QQ群,群名称:Google AdSense实战交流 群号:106483616
